1. An Architecture Blueprint for a Central Logging System
1.1. Introduction
Logging is mostly treated as a local affair: Of an application or solution, a team, or even a single developer, maybe a group thereof. But the increasing complexity of software systems increases the effort to draw the right conclusions from a large heap of heterogeneous logging records.
The trend from large monolithic application building blocks to smaller — but therefore intensely interconnected — software components is present. Therefore s IT Solutions AT (IT subsidiary of Erste Bank and Sparkassen in Austria,
www.s-itsolutions.at/) started a project to care for a central logging and journalling data lake.
The architectural pattern here is a description along the line of this "Central Logging & Journalling"
solution/application of sIT. It is targeted not at smaller systems but tries to deal with enterprises and larger IT
landscapes.
So, if you feel your path to wisdom by reading logs looks like this, you’re a happy developer already.

But if it looks a bit more like this, further reading could maybe help you.

1.2. Goals
Logging is not an end in itself — it enables many use-cases that can be grouped into four partitions:
[A]. Support: Find out about what the system did in its runtime, in order to detect the source of problems or give information to other stakeholders. Mostly use-cases here investigate in exceptional program behaviour.
[B]. Compliance: The number of regulatory use-cases increases; the run-time behaviour and intermediate data of software must be documented, often for many years.
[C]. Monitoring & Alerting: When a stream of logging data exists, it is self-evident to use this stream also to find out about the system state as well as problems and report those via multiple channels.
[D]. Analytics & Intelligence: Sophisticated tools allow data mining, BI etc. to find out ways to improve the business, may it be by exploring customer behaviour, may it by predicting operations problems, or may it be something we don’t even dream of yet.
| Support [A] | Compliance [B] | Monitoring & Alerting [C] | Analytics & Intelligence [D] |
|---|---|---|---|
* Customer Care |
* Regulatory queries
→ Long term |
* Stream analysis |
* Statistics |
1.3. Architecture
A possible architecture could make use of the following building blocks:
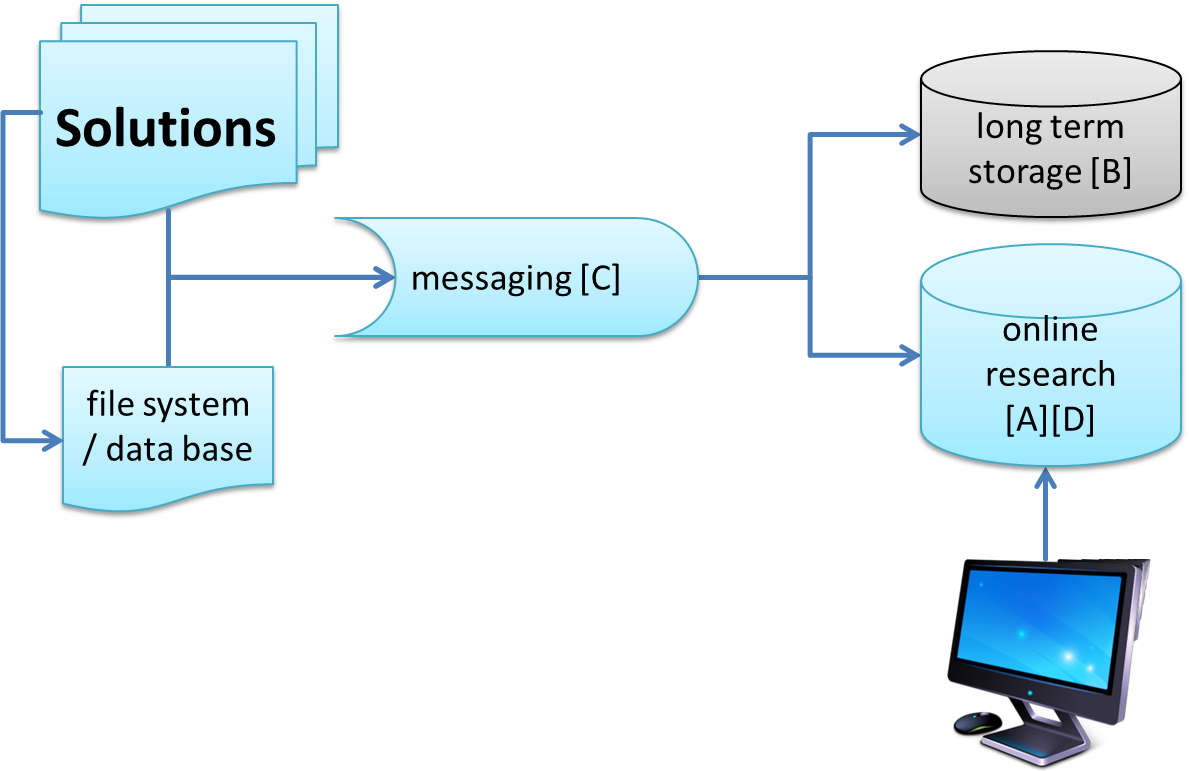
The functional as well as the non-functional, or quality, requirements of the use-case groups aforementioned are very different from each other. Therefore it makes sense to use different software products to fulfill those requirements.
1.3.1. Messaging Brick
This building block cares for a reliable (real 24/7) component where the applications can load their logging records up to. It is high-performant, lean, stable and therefore capable to also swallow extreme high-load peaks.
This building block also cares for the use-case group [C]. The type of product is queue-like, our implementation uses Apache Kafka (kafka.apache.org/). Another example would be to use Amazon’s Firehose/Kinesis in an AWS-based environment.
1.3.2. Online Research Store
This record store is responsible for the structured and fast search for log records and to find out about connections between those.
Our implementation uses ElasticSearch (www.elastic.co/de/) together with a self-written ReST service and an Angular-base front-end
1.3.3. Compliance Store
Selected log records (defined by the solution) are persisted in this record store. It is very reliable, needs a back-up, is fast with writing and stores the record before any tampering with it. On the other hand it does not need a super-sophisticated query facility.
In our implementation we decided for Apache Cassandra (cassandra.apache.org/). Other possibilities would be to store those selected records in flat files and archive them, or use a RDBMS.
1.3.4. The Client Side
The applications for logging can send their log records either directly into the messaging brick or by harvesting them from the filesystem or another data store. Both methods have pro’s and con’s.
| Direct transfer | Logfile harvesting |
|---|---|
+ Fastest |
+ Non-intrusive to existing applications |
Direct transfer
Possibilities for applications to integrate are:
-
Own client libs of messaging brick
-
APIs for creating messages that fit to the data model of CLJ
-
Appenders for existing logging frameworks (e.g. log4j2 in Java, or log.net for C#)
Generally it is a good idea to offer integration libraries that care for the situations where the messaging brick suffers from a failure. In those cases the using application should not be brought down by logging, to mitigate the tight coupling issue.
Logfile harvesting
There are a lot of tools for that use-case, ranging from light-weight native apps that are integrated into the operating system up to full-scale ETL tools (en.wikipedia.org/wiki/Extract,_transform,_load).
A few examples:
-
rsyslog (www.rsyslog.com/)
-
fluentd (www.fluentd.org/)
-
Apache flume (flume.apache.org/)
-
logstash (www.elastic.co/products/logstash, the 'L' from the famous ELK stack)
-
ElasticSearch' beat-family as feeder for the heavy-weight logstash (www.elastic.co/products/beats)
In certain architectures, some of these products could server as the messaging brick itself.
2. Central Logging Datamodel
2.1. Partitioning of the log record space
Each record has its own id value, making it unique in all of the data stores.
For managing the stores (especially the online research store for [A]), though, it is necessary to organize the records in a number of dimensions. This separation then supports in the determination of
-
Access rights/permissions
-
Retention times
-
Backup strategy
With that, the integrated applications can gain a lot of control and flexibility for their data.
The dimensions that are suggested is a combination, fitting to the actual need, of those fields:
-
tenant (in case of a real multi-tenant system with separated accounts)
-
environment (if environments are not separated pyhsically or logically on the server side)
-
solution, this determines the organizational owner of the log records within a tenant
-
recordType, to distinguish between different needs of building blocks and types of logging and journal data.
2.2. Fields
This list of fields is a gross list of common values a log system could care for. Different
applications in different contexts might use one or another subset of this enumeration, hardly setting them all. But,
and that is the main reason for this list, values of similar semantics in a log record store should be named equally, to
make traversing logs of different applications easier.
Mandatory fields are printed bold.
| Type | Field Name | Short Description | Long Description |
|---|---|---|---|
String |
id |
Technical id for the log record |
This can be set by the client (if trusted to care for uniqueness) or be omitted and set by the client. The server allow the id to be reused (=update) for semantics like records of timespans (like, e.g., sessions). Proposed algorithm is UUID. |
Header Fields, meta data of each record |
|||
String |
recordType |
Type of the record. |
This is an unbounded enumeration, it’s free to select from the solution; anyway, it is recommended to use a known value (see subpage) to make recognition of the semantics of the record easier. Record types can be shared between solutions, e.g. session, activity and techInfo are record types that are used by applications. The record type is used for partitioning the CLJ data stores for the permission system, as well as a key in defining retention periods and archiving strategy. |
String |
recordSubType |
Additional field to identify the event |
Can be used as a type of the source log record. For example, if the recordType is 'serverLog', the recordSubType could be "tomcat" oder "weblogic". |
String |
tenant |
Institute number |
If needed, for organizations serving multiple iurisdictional tenant, this is the tenant code. |
String |
environment |
Environment identifier |
If needed, when the development, test, staging, production etc. environments are not separted by dedicated data store instances but merged in one, this identifier determines from which environment a log record originates. |
DateTime-WithFractionSeconds |
recordTimestamp |
When the log record has been created |
If the client does not provide this, or the given value cannot be parsed on server side, the processing engine will create a timestamp as next best guess. |
Long |
sequence |
Determines order |
Often the record timestamp is not sufficient to discriminate and order a set of logrecords. E.g. ElasticSearch does not care for finer granularity than miliseconds. In this case the sequence field could store micros or nanos. Another possibility to use this field is that a client can care for a gapless sequence to be sure that no records are lost during transmission, procession and retrieval. A logging front-end can use this field as sole default order attribute or as secondary order attribute after recordTimestamp. |
String |
logLevel |
Level of importance, as provided by many low-level logging systems |
This field is optional, it is also not normalized, meaning that whatever the client solution provides here will be taken as-is. A lot of logging libraries have their own mind on this topic. |
User Info, information about the person or technical systems connected to the log record |
|||
String |
user |
Unique user id in its userType domain |
This identifies the user or system uniquely within the domain given in "userType". This value gets more gain in the context of current data protection laws. |
String |
userType |
Domain this user account belongs to |
Needed if different user domains should be distinguished — like internet users (customers) and intranet users (employees). Or when user domains ob subsidiaries are not clearly separated by the user ids. |
Source Info, which component wrote this log record |
|||
String |
solutionCode |
Unique identifier of a solution |
Identifies the Solution as unit in the IT landscape. |
String |
solutionFunctionCode |
Id of functional building block |
If needed, more fine-grained organizational partitioning. |
String |
sourceApplication |
Building block |
More technical/architectural paritioning key. |
String |
sourceHostname |
System name of the server initiating the logging call |
e.g. DNS of physical or virtual system |
String |
sourceIp |
Client IP, originator of the log |
The value might differ in regard of the nature of the originator (e.g. a browser-based application, or a batch) |
String |
userAgent |
Software that initiated the call |
This field is used when the software and its version of the user/client is relevant. e.g. In web front-ends this identifies the Browser that has been used. The writing solution can give any information if it thinks that information about its caller makes a difference. |
String |
agentVersion |
TODO |
deprecated, might be removed in the future. |
String |
serverInstanceName |
Identifies the server instance |
e.g. the docker pod |
Initiating solution |
|||
String |
clientId |
Code from initiating system |
Inititiating systems are mostly user front-ends or batch processes. |
Harvesting Info, where was the log record first persistet, might be different from the source solution |
|||
String |
sourceType |
Syntax of the incoming data |
Syntax of the incoming data (into the messaging brick). 'generic' means using this data model in JSON, this is the default value. If the syntax is not 'generic' the central logging service might be able to to a proper transformation. |
String |
loggingHostname |
Server Host Name |
like sourceHostname |
String |
loggingHostIp |
Server IP address |
The system that provided the logging information, e.g. Apache host for access logs, or any other harvisting service running logstash, fume, rsyslog or a similar tool. |
String |
logFile |
file name and path from which the log record has been harvested, if applicable |
If logrecords are not sent directly to the messaging building block, but harvested from a logfile (by Logstash or a similar software) here this filename and path of the appropriate format (Windows, Unix, Mainframe, …) can be sent if needed. |
Context |
|||
String |
parentId |
Hierarchical predecessor of this log record. |
Could be of a functional or sequential order Here a key of a hierarchical higher-level record can be set. So a tree-like structure of log records can be created. |
String |
contextId1 |
Mapping context id field 1 |
Example: The id of a user session. |
String |
contextId2 |
Mapping context id field 2 |
Example: The (use case) id of a user’s activity. |
String |
contextId3 |
Mapping context id field 3 |
Example: The id of a explicit technical log record. |
String |
contextId4 |
Mapping context id field 4 |
|
DateTime-WithFractionSeconds |
startDate |
Start date of the record |
For journalling records that have a time span, this field of the event signals the begin timestamp. |
DateTime-WithFractionSeconds |
endDate |
End date of the session |
For journalling records that have a time span, this field of the event signals the end timestamp. |
String |
correlationId |
Correlation ID for a synchronous or quasi-synchronous call |
Unique Id that is created as early as possible (ideally by the initiator) and then guided through the whole call hierarchy to create traces of calls. |
Unstructured and semistructured data |
|||
String |
message |
Log Message |
All the information that is not part of other fields |
String |
additionalInfo |
semi-structured data |
Business or other data. Technically this is a text field. It is recommended, though, to use JSON syntax, because the front-end can interpret it and display a tree structure. Special Case of additionalInfo: External Links. This can be rendered in the UI as Link with following Syntax: additionalInfo.extlink.ref : The URI for the external Link; additionalInfo.extlink.name : The DisplayName for the Link. |
Result section |
|||
String |
resultCode |
Code if the record represents a task of any kind |
HTTP record code, Exception, Error |
String |
errorMessage |
Error Message |
Any standardized code or message the sending solutions wants to log. |
Boolean |
businessError |
Business Error |
Sometimes business errors are stored as normal messages. It is up to the application to decide which message is a business error or a message. This value should be true for business errors |
Status |
normalizedStatus |
Status field red/yellow/green |
This field is for the user, giving a hint about whether this log record represents ok status, a warning or an error. enum Status { red yellow green } |
Technical information |
|||
String |
thread |
Name of the server thread |
|
String |
logger |
Software origin |
Name of the class and method(optional) which logs this message |
Long |
durationMs |
Duration of a call in milliseconds |
|
String |
logProcessingError |
StackTrace of the log processing error. |
This is not provided by the client solution but used if anything goes wrong in CLJ log record processing. |
3. About CLJ
CLJ is a proposal to harmonize logging in an environment where multiple software building blocks are working together in order to fulfill shared requirements.
|
CLJ is a design blue-print, a proposal how to align a share logging environment.
|
Authored by the CLJ team in www.s-itsolutions.at [s IT Solutions AT], lead by Klemens Dickbauer.